
Chasing Medicare Fraud with Machine Learning

Machine learning can help detect Medicare fraud, but what is the tradeoff between human v.s machine?
The words “machine learning” and “healthcare” together often conjure images of IBM Watson and the potential to transform who provides medical care and how. But machine learning’s applications are much broader, and play an extremely important role in saving money in the healthcare insurance world. In particular, the government agency the Center for Medicare & Medicaid Services (CMS) and other private insurance companies have adopted predictive analytics and machine learning techniques in order to better detect fraud and prevent medical billing errors1,2. With the implementation of these techniques, a larger question also arises: how much do we trust computer algorithms and what should be their scale and scope in comparison to human-driven analysis?
Fraud and medical billing errors represent a huge cost in the U.S healthcare system. CMS’s Medicare—a public insurance largely serving Americans 65 years and older—is estimated to dole out 6 billion dollars due to fraud every year, representing about 10% of its 60 billion dollar annual expenditures3,4. Machine learning plays an innovative role in fraud detection because it can very quickly predict potential fraud cases based on past available data.
Broadly speaking, a model that predicts fraud can be created through “supervised” or “unsupervised” machine learning. In “supervised” machine learning, the computer would be fed billing data or “claims” created by physicians that have seen Medicare patients, as well as data about known fraudulent cases5. The computer would then build a model based on connections it draws between the two datasets so if the computer is given a new claim, the model could predict if it’s fraudulent or not5.
On the other hand, “unsupervised” learning occurs when the computer is only given Medicare claims data and tries to detect meaningful patterns in order to predict future fraud, usually through “cluster analysis”5. Cluster analysis uses statistical methods to split claims data into various groups through a few dimensions of the data—for instance, where the physician is located, how many procedures they do5,6. Based on these clusters, the resulting outliers represent claims/medical providers that exhibit suspicious patterns of activity that could indicate fraud (see Figure 1).
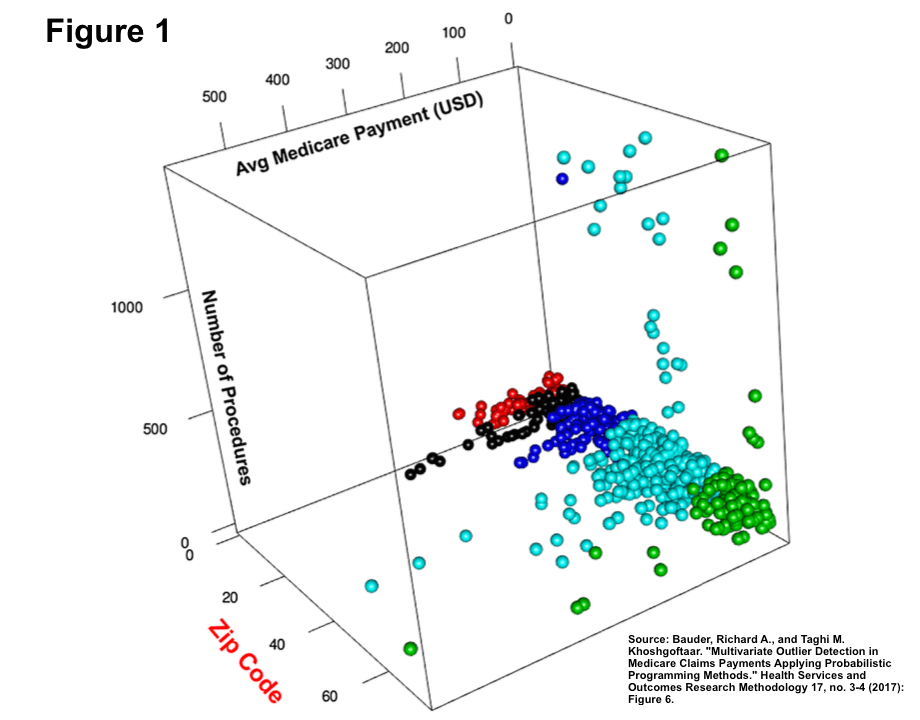

So, are these types of algorithms the end game for fraud detection? For CMS and Medicare, they are far from it. At CMS, its Fraud Prevention System (FPS) functions as a way to generate leads for investigation by identifying outliers in the data and flagging cases for potential fraud3. In recent years, FPS has been increasingly incorporated into the fraud investigation workflow, generating 5% of all leads investigated by CMS in the beginning years, up to 20% more recently in 2015-163. While this amounts to 1.4 billion dollars of savings, these FPS leads still require extensive non-automated “manual” investigations by CMS or government-contracted employees3,9.
In the short to medium term, Medicare is planning on forming many different partnerships with other insurance companies and stakeholders to improve its fraud detection process. It is also focusing on standardizing the process for how employees investigate leads. However, even with the FPS revamping in 2017, in the next ten years the technology will likely continue to function as is—generating a wider funnel of potential fraud cases that will not necessarily save many labor-hours7,8. CMS should consider how it can better maximize the utility of its technology in its current human-labor intensive process. In the next ten years FPS technology is likely to improve drastically and produce fewer false positives, and FPS should be incorporated more broadly in Medicare’s payment system10. In particular, CMS could consider stopping payments for potential fraudulent claims before a human even lays eyes on the data so CMS doesn’t have to “pay-then-chase” after cases that may not have warranted payment due to fraud.
However, some questions still remain regarding the tension between the computer driven and human driven processes. In particular, policies in health insurance change frequently, and even the coding system for medical claims changes as well. How do we think about compensating for these changes that can make the dataset inconsistent, or much smaller? Should machine learning play a smaller role in the beginning years after these types of change? On the converse side, if we move towards better technology and machine learning algorithms, could we potentially completely remove human oversight for this process? Would that be ethical?
(711 words)
Endnotes:
1“Aetna Is Taking on Insurance Fraud with Machine Learning.” Arcweb Technologies. Accessed November 13, 2018. https://arcweb.co/aetna-fraud-machine-learning/.
2 United States Government Accountability Office, Medicare, CMS Fraud Prevention System Uses Claims Analysis to Address Fraud: Report to Congressional Requesters. By Kathleen King. 2017.
3 Fred Schulte, “Fraud And Billing Mistakes Cost Medicare – And Taxpayers – Tens Of Billions Last Year.” Kaiser Health News. July 19, 2017. Accessed November 13, 2018. https://khn.org/news/fraud-and-billing-mistakes-cost-medicare-and-taxpayers-tens-of-billions-last-year/.
4 Lewis Morris, “Combating Fraud In Health Care: An Essential Component Of Any Cost Containment Strategy,” Health Affairs Vol 28 No. 5, 2009.
5 Hossein Joudaki, Arash Rashidian, et al., “Using Data Mining to Detect Health Care Fraud and Abuse: A Review of Literature,” Global Journal of Health Science 7, no. 1 (2014): , doi:10.5539/gjhs.v7n1p194.
6 Bauder, Richard A., and Taghi M. Khoshgoftaar. “Multivariate Outlier Detection in Medicare Claims Payments Applying Probabilistic Programming Methods.” Health Services and Outcomes Research Methodology 17, no. 3-4 (2017): 256-89. doi:10.1007/s10742-017-0172-1.
7 United States Government Accountability Office. Medicare Fraud – Further Actions Needed to Address Fraud, Waste, and Abuse: Testimony before the Subcommittee on Oversight and Investigations, Committee on Energy and Commerce, House of Representatives. By Kathleen King. 2014.
8 “CPI Investing In Data and Analytics.” CMS.gov Centers for Medicare & Medicaid Services. April 19, 2018. Accessed November 13, 2018. https://www.cms.gov/About-CMS/Components/CPI/CPI-Investing-In-Data-and-Analytics.html.
9 Center for Medicaid and Medicare Services. Fraud Prevention System Return on Investment, Fourth Implementation Year. 114th Cong.
10 Korte, Travis. “How CMS Can Improve Its Fraud Prevention System.” Center for Data Innovation. May 04, 2018. Accessed November 13, 2018. https://www.datainnovation.org/2014/10/how-cms-can-improve-its-fraud-prevention-system/.
Very interesting and informative read! Presumably, as policies change, the clustering technique may interpret new payments as being fraudulent since they may appear as outliers relative to its previously amassed information. Therefore, I agree that when a new insurance policy is rolled out, the insurance companies should rely less heavily on AI. That being said, as you mentioned, with the evolution of technology, the time required to recognize fraudulent charges is expected to decrease.
Great article, Christine! Using machine learning to detect fraud in medical billing raises some ethical questions. On one hand, Medicare focus should be on making the best use of the taxpayer money and reducing unnecessary costs. However, on the other hand, I am worried about overlying on machine learning to detect frauds. What would happen in the case of a false positive (detected as a fraud but honest medical expense)? Would that lead to patients that get their treatments covered anymore? I think the use of technology is effective – and needed – to control rising medical expenditures but human oversight should be preserved to ensure coverage for all ‘honest patients’.