
Aetna: Artificial Intelligence Goes After Health Care Fraudsters

US health care payers lose billions of dollars per year to insurance fraud, waste, and abuse. Payers turn to machine learning to revolutionize outdated manual review processes and improve the bottom line.
McKinsey estimates that US health care insurance companies could reduce fraud waste, and abuse (FWA) by $20-30 billion by using machine learning [1]. Historically most of the fraud detection in health care insurance has been handled through manual review and basic automation. This is changing now. More companies have started to look into machine learning to enable more efficient fraud detection.
As any major US health care insurance provider, Aetna processes and pays hundreds of thousands of claims per month. Aetna’s SIU (Special Investigation Unit) focuses on identifying and investigating instances of fraud, waste, and abuse. SIU analyzes claims and patient data to uncover cases of overbilling, incorrect coding, excessive services, and duplicate claims. However, it’s not remotely possible to manually process and investigate every single claim that comes through the billing pipeline, which means that an unknown volume of fraudulent claims is being paid every month, resulting in a value loss for Aetna and its customers.
Building a machine learning platform for fraud detection
Aetna’s Analytics and Behavioral Change Organization works on applying advanced analytics and machine learning to solve different business problems within the organization. Several years ago it partnered with Aetna’s SIU to transform fraud detection and recovery process.
The starting point was to build a data pipeline. Due to the complexity of the data and variety of formats and storage locations, it usually is one of the most time-consuming tasks to bring all the data together in a format that allows applying machine learning techniques to it.
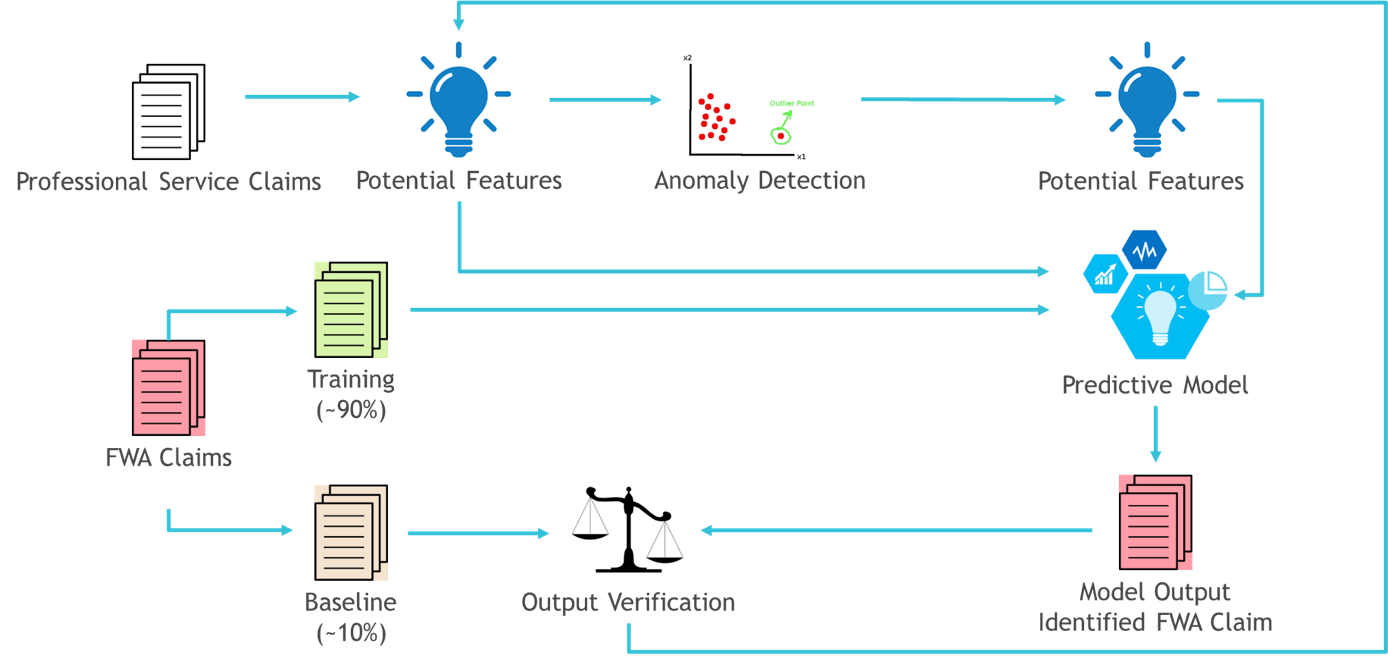
The next step was to build and train machine learning models which generally fell into two categories. The first category aimed at spotting the signs of fraud that wasn’t new to Aetna. Those models were trained with existing data from recovered FWA claims. Among examples of such fraud was an abnormally large number of patients per day or an unusual repeated combination of Current Procedural Terminology (CPT) codes in provider’s claims. The second and most advanced category helped to identify outlier repeating patterns in the data which might signal a new type of fraud.

However, work didn’t stop with building and training the models. Another critical task was to integrate the model’s output in current business operations. Aleksandar Lazarevic, a senior director at Aetna’s analytics organization, who is also in charge of the machine learning fraud detection program, says: “We didn’t build only the data pipeline, we were also able to build a tool that automatically sends all our findings to SIU.”[2]
Going forward Lazarevic’s team plans to focus on proactive detection and prevention of emerging fraud patterns as well as uncovering the inefficient use of provider services and even areas of insufficient provider coverage.
What’s next?
One of the biggest challenges of machine learning initiatives is acquiring and retaining technical talent – data scientists and machine learning developers [3]. However, to fully realize the potential of cutting-edge technology and tightly integrate it in company’s daily operations, Aetna should also focus on hiring and training employees that will bridge the gap between technical and business teams. These employees will combine a thorough understanding of claim payment processes with knowledge of statistics, analytics, and machine learning techniques. By leveraging cross-functional skillset, they will be able to identify high impact cases for machine learning application from a business perspective and work with technical teams to ensure that technology closely follows business needs.
BCG estimates that after the claim has been paid, the probability of recovering the money is approximately 1%. It is also way less costly to hold and analyze incoming claim than investigate and recover the one that has already been paid [4]. Current application of machine learning to fraud detection mostly focuses on identifying FWA in paid claims with further recovery. One of the areas where Aetna could focus machine learning initiatives is identifying and holding suspicious claims before they are processed.
Challenges remain
Current machine learning algorithms mostly rely on uncovering fraudulent patterns in historical data and applying the findings to spot fraudulent activities on new data. However, insurance fraud schemes are continually evolving. Fraudsters come up with brand new ways to game the system every day. One of the questions is – how could machine learning be used to effectively spot fraudulent patterns that have never occurred before?
Another important question is how to overcome obstacles to machine learning adoption in a large organization where challenges such as intense competition for technical talent on the market, fragmented data systems, subpar data quality and lack of long-term machine learning implementation strategy might get in the way [5].
(760 words)
Sources
[1] Healthcare.mckinsey.com. (2018). Using machine learning to unlock value across the healthcare value chain. [online] Available at: https://healthcare.mckinsey.com/sites/default/files/2018_Using-machine-learning_Infographic.pdf [Accessed 8 Nov. 2018].
[2] Schiller, K. (2018). Aetna is taking on insurance fraud with machine learning. [online] Available at: https://arcweb.co/aetna-fraud-machine-learning/ [Accessed 8 Nov. 2018].
[3] Marr, B. (2018). The AI Skills Crisis And How To Close The Gap. [online] Available at: https://www.forbes.com/sites/bernardmarr/2018/06/25/the-ai-skills-crisis-and-how-to-close-the-gap/#78d90d8b31f3 [Accessed 10 Nov.2018].
[4] Selikowitz, D. (2018). The right medicine: three practical steps to reduce the cost of public health fraud. [online] Available at: https://www.centreforpublicimpact.org/three-practical-steps-reduce-cost-public-health-fraud/ [Accessed 10 Nov. 2018].
[5] Falcon, W. (2018). 4 Reasons Why Companies Struggle To Adopt Deep Learning. [online] Available at: https://www.forbes.com/sites/williamfalcon/2018/07/05/4-reasons-why-companies-struggle-to-adopt-deep-learning/#53e2d65b4cda [Accessed 10 Nov. 2018].
Really interesting post! In regards to your first question (“how can machine learning detect frauds that have never happened before”) I think there are two answers. The first is a simple one – could humans detect frauds that have never happened before? My guess would be that the old system would be no better than the new system in this case, in that both would miss the fraud, so there is no incremental loss in using the machine learning capability. However, I think machine learning actually might be able to detect this new fraud, if the data was still irregular in some way – it might not understand how the data came to be this way, but it could still flag as irregular.
The other question I have is a broader strategic one – how does the use of this tool affect customer satisfaction? And, could it actually become a competitive disadvantage in that so many consumers get flagged as “potential fraud” that they find dealing with Aetna unwieldy, and move their business elsewhere. So, I would be worried about the rate of “false positives” that this method produces.
Fascinating topic and extremely well-written essay.
First, let me echo how important such a tool is to the healthcare market. In Brazil, for example, it is estimated that around US$ 4 billion are wasted due to frauds or exams that weren’t necessary at all, even if there’s no direct “fraud” involved.
As to your question about detecting new frauds, that is the purpose of the algorithms described as unsupervised machine learning, which essentially try to predict patterns without any prior training phase. It is the case of Google clustering related news even without prior knowledge of what the news would be. Or, more relevant to the topic here, it is the case of a project in Brazil called Operation Love Serenade that uses machine learning to monitor public spending and identify frauds without the ability to train the algorithm with the types of frauds that would be used. They achieve that my letting the algorithm discover what are the outliers or suspicious patterns that are starting to emerge in the data.
Another potential application of this tool for Aetna is identifying combinations of exams that do not make sense (or whose order seem to be wrong). For example, a payer could question a provider as to why Exam B was performed if Exam A is unequivocally more comprehensive and had been done before exam B. That wouldn’t be classified as fraud but is likely to be considered waste.
Really enjoyed this! I know you asked a question about how machine learning could be used to effectively spot fraudulent patterns that have never occurred before, and I wanted to expand on this. I think that your question gets at one of the fundamental principles of machine learning — the idea that as data (in this case, fraud data) continues to evolve and change, one must feed these new data into the machine learning algorithm in order to refine it.
I would go a step further and ask the question: how can machine learning in this case adapt to ever-changing medical practices and protocols? For example, while use of a medication for a certain disease may have been considered wasteful in 2010, it might not be considered wasteful in 2018 (or vice versa), given that medical practice is constantly changing. It will be quite a challenge to update these new protocols and practices in the context of rapidly evolving medical standards. However, as you argue in your piece, these efforts will likely be worthwhile given the potential applications of machine learning to the health insurance industry.